Page
1.4 The FAIR data principles
In the interview with Kenneth Ruud, there was mention of the term FAIR principles. These principles were drafted in 2014 during an international meeting and published in 2016 by Wilkinson et al.. The FAIR principles are a set of guidelines developed to optimise the reusability of research data, and they form the basis for the good research data management practices introduced in this online course. Learn more about what is behind the acronym FAIR in the following video:
Transcript of video "The FAIR data principles"
Lessons learned
- Findable: The first step in (re)using data is to find them. Metadata and data should be easy to find for both
humans and computers.
- Accessible: Finding a dataset does not automatically mean access to the data. The reference must be persistent, and the data files must be accessible.
- Interoperable: The repository must be machine harvestable, and metadata must follow standards, to allow data to be combined with data from other repositories. Repositories need to interoperate with software or workflows for storage, processing, and analysis.
- Reusable: The ultimate goal of FAIR is to optimise the reuse and control of data. To achieve this, metadata and data should be well documented so that the analysis can be reproduced and/or data be reused in other ways.
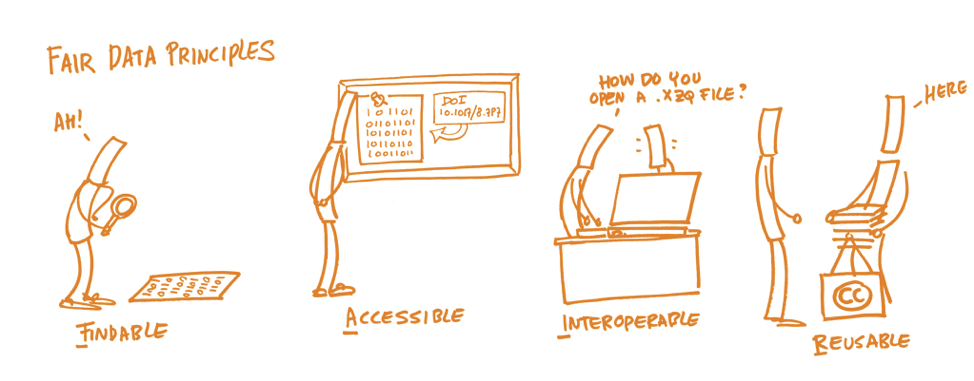
Figure: "Assessing the FAIRness of data" by FOSTER is licensed under CC0
Recommended reading if you want to learn more:
- CESSDA: FAIR data. https://www.cessda.eu/Training/Training-Resources/Library/Data-Management-Expert-Guide/1.-Plan/FAIR-data
- Deutz et al. (2020): How to FAIR: a Danish website to guide researchers on making research data more FAIR. https://howtofair.dk/what-is-fair/
- OpenAIRE: How to make your data FAIR? https://www.openaire.eu/how-to-make-your-data-fair
- Wilkinson, M., Dumontier, M., Aalbersberg, I. et al. (2016). The FAIR Guiding Principles for scientific data management and stewardship.
Sci Data 3, 160018. https://doi.org/10.1038/sdata.2016.18
Last modified: Tuesday, 20 December 2022, 3:40 PM