2.3 Data and the long tail of research
Hiding within those mounds of data is the knowledge that could change the life of a patient, or change the world.
– Atul Butte, Professor in Paediatrics at University of California, San Francisco
Research datasets come in all shapes and sizes, and confronted with this, the knee-jerk reaction might be to think that big is more valuable than small. Big datasets are often generated in large, collaborative, externally funded projects, and tend to receive much attention. But Borgman (2015) touches upon something important when she says that “[h]aving the right data is usually better than having more data” (p. 4) and as such implies that relevance does not necessarily increase proportionally with quantity. In too many cases the right data are not available. Such data may have been collected, but they may be hard to find, locked behind technical barriers, not well curated, or the owner may be reluctant or unwilling to share them. So lacking "the perfect data", we need to make the best out of the data available.
A common way to illustrate the availability and use of research data is through the long tail metaphor (Anderson, 2004), see figure below. The head of the curve represents a small number of researchers that work with data that are large in quantity, while the long tail represents the large majority of researchers, who work with small- or medium-sized data.
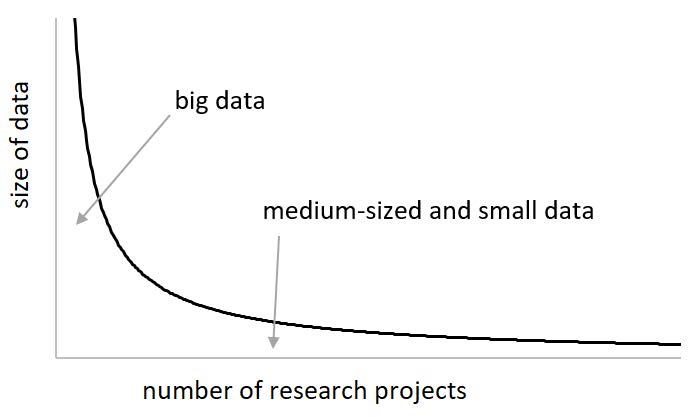
Figure: "Distribution of research projects according to data size" by Conzett (2020, p. 81) is licensed under CC BY 4.0
Research data collected in large volumes tend to be homogeneous in nature and content, collected using uniform procedures, and curated using standardised protocols. Research data collected in smaller volumes, on the other hand, tend be more heterogeneous. Smaller projects are often carried out by individuals or smaller research teams. They enjoy more flexibility and less need for standardization in the collection and curation process, but tend to go unnoticed. These small- and medium-sized datasets taken together represent a considerable portion of the scientific output in the world, and let us illustrate their importance using a metaphor from the entertainment industry (see Anderson, 2004; Heidorn, 2008): A plethora of feature films are released each year, but few reach high viewership numbers. This does not mean that the other feature films – less “blockbuster” in nature – have less value: Given the fact that there are thousands of them, the few interested viewers per film do in total make a significant number. If you're fan of a given cinematic tradition, we're quite sure you can relate to this!
To cite Heidorn (2008, p. 282), “[t]he long tail is a breeding ground for new ideas”. At the same time, these data suffer from the lack of infrastructure and curation support that often come with bigger data, and they tend to be harder to find and harder to reuse, and as such run a higher risk of being lost or forgotten about. Luckily, this problem is now taken seriously and addressed by major research funders, such as the European Commission:
Despite considerable progress in recent years, [...] subject coverage of repository and data resources remains patchy. The so-called ‘long tail’ of research remains poorly catered for, and vast amounts of data produced in research are not FAIR and currently lack long-term stewardship. As such, these data are largely lost to science and represent a significant loss of investment. (European Commission, 2018, p. 55).
References
- Anderson, C. (2004). The long tail. Wired Magazine, 12(10). Retrieved 25.02.2021 from https://www.wired.com/2004/10/tail/
- Borgman, C. L. (2015). Big data, little data, no data: Scholarship in the networked world. MIT Press.
- Conzett, P. (2020). DataverseNO: A National, Generic Repository and its Contribution to the Increased FAIRness of Data from the Long Tail of Research. Ravnetrykk, 39. 74-113. https://doi.org/10.7557/15.5514
- European Commission. (2018). Turning FAIR into reality: Final report and action plan from the European Commission expert group on FAIR data. Publications Office of the European Union. https://op.europa.eu/s/n1Yo
- Heidorn, P. B. (2008). Shedding light on the dark data in the long tail of science. Library Trends, 57. 280-299. https://doi.org/10.1353/lib.0.0036